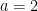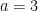Today I was due to speak at the Isaac Newton Institute’s workshop on “Interactions between group theory, number theory, combinatorics and geometry”, which has obviously been canceled. I was going to speak about my work on the Hall–Paige conjecture: see this earlier post. Meanwhile Péter Varjú was going to speak about some other joint work, which I’d like to share with you now.
Consider (if you can consider anything other than coronaviral apocalapyse right now) the random process in defined in the following way: (or any initial value), and for
Here we take to be a fixed integer and a sequence of independent draws from some finitely supported measure on . As a representative case, take and (uniform on ).
Question 1 What is the mixing time of in ? That is, how large must we take before is approximately uniformly distributed in ?
This question was asked by Chung, Diaconis, and Graham (1987), who were motivated by pseudorandom number generation. The best-studied pseudorandom number generators are the linear congruential generators, which repeatedly apply an affine map . These go back to Lehmer (1949), whose parameters and were also subject to some randomness (from MathSciNet, “The author’s proposal for generating a sequence of `random’ 8 decimal numbers is to start with some number , multiply it by 23, and subtract the two digit overflow on the left from the two right hand digits to obtain a new number .”) The process defined above is an idealized model: we assume the increment develops under some external perfect randomness, and we are concerned with the resulting randomness of the iterates.
My own interest arises differently. The distribution of can be thought of as the image of under the random polynomial
In particular, if and only if is a root of . Thus the distribution of is closely related to the roots of a random polynomial (of high degree) mod . There are many basic and difficult questions about random polynomials: are they irreducible, what are their Galois groups, etc. But these are questions for another day (I hope!).
Returning to Question 1, in the representative case and , CDG proved the following results (with a lot of clever Fourier analysis):
The mixing time is at least
This is obvious: is supported on a set of size , and if then , so at best is spread out over a set of size .
The mixing time is never worse than
Occasionally, e.g., if is a Mersenne prime, or more generally if has small order mod (or even roughly small order, suitably defined), the mixing time really is as bad as that.
For almost all odd the mixing time is less than
You would be forgiven for guessing that can be replaced with with more careful analysis, but you would be wrong! In 2009, Hildebrand proved that for all the mixing time of is at least
Therefore the mixing time of is typically slightly more than . What is going on here? What is the answer exactly?
In a word, the answer is entropy. Recall that entropy of a discrete random variable is defined by
Here are some basic facts about entropy:
If is uniform on a set of size then .
Entropy is subadditive: the entropy of the joint variable is at most .
Entropy cannot be increased by a (deterministic) function: .
By combining the second and third facts, we have the additive version (in the sense of adding the variables) of subadditivity:
and hence by the subadditive lemma converges. (We are thinking now of as a random variable in , not reduced modulo anything.) Call the limit .
It is easy to see in our model case that (because has support size ). If , then it follows that the mixing time of is strictly greater than (as cannot approach equidistribution mod before its entropy is at least ).
Indeed it turns out that . This is "just a computation": since , we just need to find some such that . Unfortunately, the convergence of is rather slow, as shown in Figure 1, but we can take advantage of another property of entropy: entropy satisfies not just subadditivity but submodularity
and it follows by a short argument that is monotonically decreasing and hence also convergent to ; moreover, unlike the quotient , the difference appears to converge exponentially fast. The result is that
so the mixing time of is not less than
(We can also deduce, a posteriori, that we will have for , though it is out of the question to directly compute for such large .)
Figure 1: The entropy difference rapidly converges. Predicted values are dashed.
This observation was the starting point of a paper that Péter and I have just finished writing. The preprint is available at arxiv:2003.08117. What we prove in general is that the mixing time of is indeed just for almost all (either almost all composite coprime with , or alternatively almost all prime ). In other words, entropy really is the whole story: as soon as the entropy of is large enough, should be close to equidistributed (with a caveat: see below). The lower bound is more or less clear, as above. Most of the work of the paper is involved with the upper bound, for which we needed several nontrivial tools from probability theory and number theory, as well as a few arguments recycled from the original CDG paper.
However, just as one mystery is solved, another arises. Our argument depends on the large sieve, and it therefore comes with a square-root barrier. The result is that we have to assume . This is certainly satisfied in our representative case (as the entropy is very close to ), but in general it need not be, and in that case the problem remains open. The following problem is representative.
Problem 2 Let and let . Then is uniform on a (Cantor) set of size , so . Show that the mixing time of is for almost all primes .
You might call this the “2–3–4–5 problem”. The case is trivial, as is uniform on . The case is covered by our main theorem, since . The case is exactly borderline, as , and this case is not covered by our main theorem, but we sketch how to stretch the proof to include this case anyway. For we need a new idea.




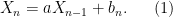




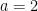
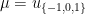

in
before
is approximately uniformly distributed in




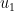

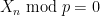
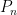


, and if
then
, so at best
.


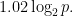





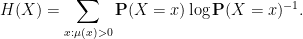
then
.
is at most
.
.




















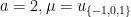

and let
. Then
, so
. Show that the mixing time of
for almost all primes